Sztuczna inteligencja - czeladnik mistrza
Mariusz Pisarski | 29.04.2023
Serią ilustracji stworzonych przy pomocy silników AI podzielił się w mediach społecznościowych poeta Jason Nelson. Nie byłoby w tym nic dziwnego, gdyby po pierwsze chodziło o zwykłe owoce naszych kreatywnych potyczek z sztuczną inteligencją, a po drugie gdyby tożsamość autorska pracy nie przechylała się w tym przypadku – wyjątkowo – w kierunku stylu i tożsamości człowieka, a nie maszyny. Paradoksalnie kluczem do “uczłowieczenia” prac okazuje się ta sama ilościowa metoda, która przyczyniła się do sukcesów modeli GPT , nazywanymi nie bez powodu modelami uczenia maszynowego o “o dużej skali”, a zatem czerpiącym z tysięcy terabajtów językowej i wizualnej ekspresji publikowanej w internecie i gromadzonej w przeróżnych sieciowych archiwach i repozytoriach. Otóż każdą z ilustracji stworzonych przy współudziale GPT Nelson stworzył nie za pomocą pojedynczego zapytania i pojedynczej odpowiedzi, ale za pomocą kilkudziesięciu prompów i setek “generatywnych ramek”. Ta ilościowa metoda skutkuje kolażową, kompozytową ilustracją o dużej rozdzielczości (10k). Następnie autor sięga po metody jakościowe, przerabiając otrzymany surowy materiał w obrębie wyłaniającego się graficznego kolażu przy pomocy dziesiątek “punktów wymazywania i ponownego rysowania”. Efektem takich metod jest choćby poniższy Ultra-Large Digital Narrative Image No.4:

Celem całej serii, jak wyjaśnia Nelson, było stawienie wyzwania “zgrzytliwej akceptacji” i “pełzającej pogardy” wyrażanej przez artystyczną społeczność wobec wytworów sztucznej inteligencji. Wydaje się, że cel ten został osiągnięty. Ilustracje, którymi Nelson się podzielił, choć noszą widoczne ślady działania modeli sieci neuronowych, której “gust”, jak udowadniają złośliwi krytycy, nieustannie ciąży ku estetyce okładek albumów psychodelicznego rocka z lat 70., posiadają też ewidentne oznaki stylu własnego Nelsona. Wystarczy porównać je z wyróżnioną niedawno poetycką grą Nelsona The Many Occasions of Moving (2022), czy nawet z jego ręcznie zrobioną, drewnianą skrzynką reprezentującą analogowy interfejs poetyckiej wyobraźni nadesłany na festiwal Pixel (2016), aby dostrzec wiele stylistycznych i konceptualnych kontynuacji…. :

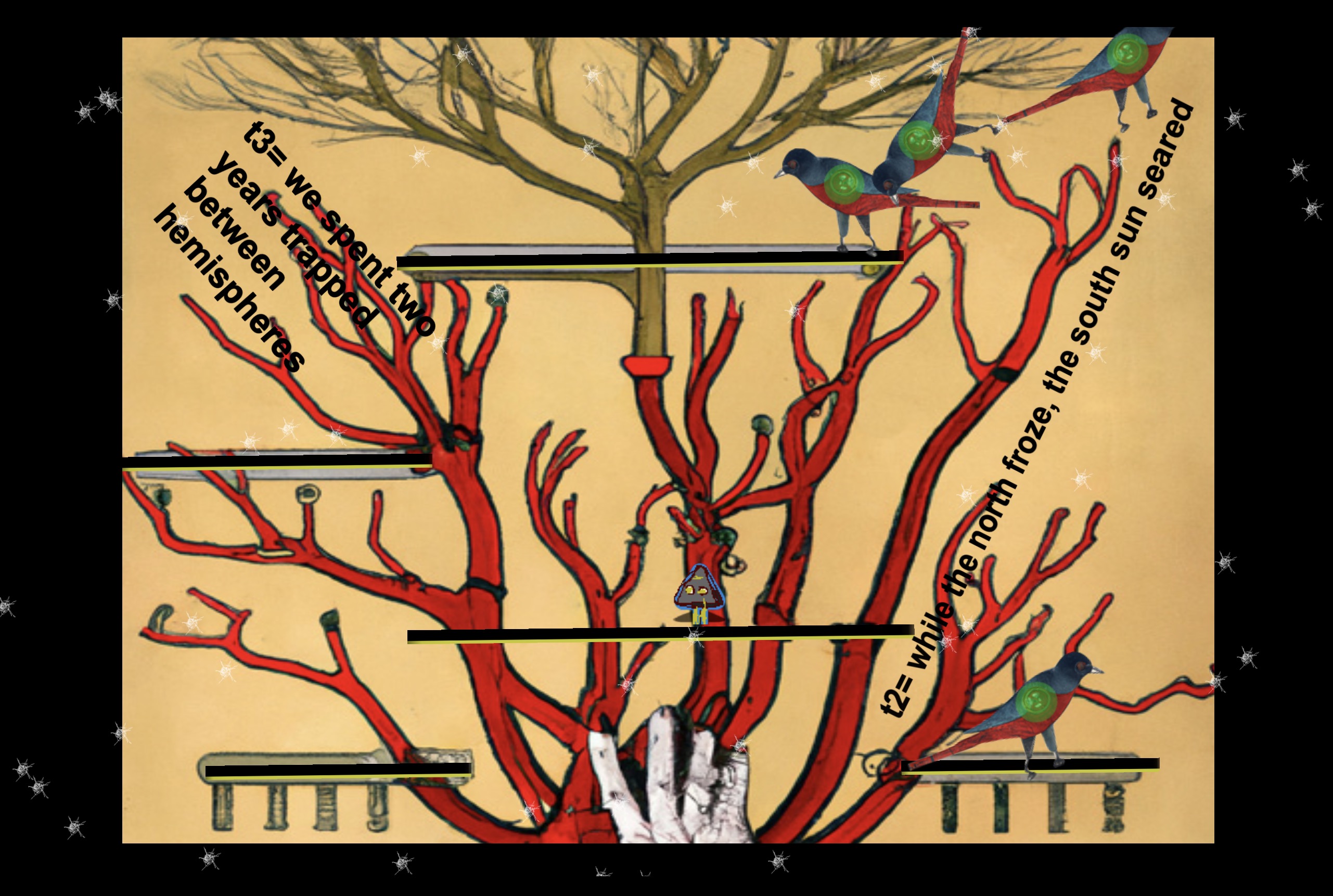
Wykorzystane umiejętnie, modele sztucznej inteligencji zdają się wyraźnie służyć artyście, a nie mu zagrażać. Traktowanie GPT jako czegoś na wzór czeladnika mistrza w dawnych warsztatach malarskich wydaje się ważnym krokiem do zbalansowanego podejścia do potencjalnych zagrożeń. Nelson to podkreśla: “to jestem ja plus SI… te obrazki są bardziej skomplikowane niż prosty prompt i skutkująca nim grafika, dużo bardziej skomplikowane. Ale oczywiście SI odwalą tu kawał dobrej roboty”. Debata rozpoczęta przez prowokatorów takich jak Boris Eldagsen, który za pracę stworzoną przez SI otrzymał nagrodę w konkursie Sony World Photography Award, szybko się nie zakończy. Niemniej jednak, im więcej będzie przypadków, kiedy to artysta zyskuje raczej niż traci na postępie technologii SI, tym wyraźniejszy będzie jej wynik.
Storylets – nowe funkcje programu Twine
Mariusz Pisarski | 30.04.2023
Kolejne ciekawe zmiany przynoszą nowe wersje programu Twine. Ostatnio w silniku Harlowe pojawiły się nowe makra określane mianem storylets. Zainspirowane proceduralnymi dialogami z gry Façade, wykorzystywane w Fallen London i w innych grach Emily Short, a niedawno wprowadzone do popularnego silnika Harlowe w Twine, storylets obiecują projektowanie nieliniowych narracji w sposób atrakcyjniejszy i dla autora i dla czytelnika (gracza). Emily Short definiuje storylets jako “niewielkie kawałki treści narracyjnej (wydarzenia, fragmenty) posiadające warunki wstępne, które określają, kiedy dana treść jest "odtwarzana", oraz efekty końcowe, które następują po "odtwarzaniu" danej treści.

Dotychczasowe omówienia kategorii storylets, oraz sama dokumentacja Twine, nie mówią zbyt wiele o korzeniach tej figury, a szkoda. Na poziomie skryptu pojedynczego segmentu opowieści, „warunki wstępne” oraz ich efekty można odnaleźć już w najwcześniejszych grach tekstowych (jeśli masz klucz, otwierasz drzwi do następnej lokacji) oraz w pionierskich hipertekstach jak popołudnie. pewna historia (jeśli nie wiesz kim jest Lolly, nie przejdziesz do jej gabinetu). Na poziomie grupy segmentów i dynamicznie wytwarzanych relacyjnych sekwencji storylets wywieść można z narracji budowanych na zasadzie talii kart, gdzie poszczególne segmenty rozdawane są jak w grze karcianej, a rozdanie z grupy obwarowane jest jakąś regułą (logiczną, frekwencyjną). Metody talli kart, jako element tzw. hipertekstu rzeźbiarskiego (sculptural hypertext) są wbudowane w najnowszą edycję Storyspace 3 i ich sztandarową demonstracją pozostaje powieść Those Trojan Girls Marka Bernsteina. Storyspace i Twine, każdy program na swój sposób, oferują też rozbudowany arsenał wymogów, warunków i działań, jakie przypisać można do pojedynczego linku, segmentu, otagowanej sekwencji.
Na kursach sztuki pisania, groznawstwa czy mediów cyfrowych, kategoria storylets może okazać się przydatna w zilustrowaniu wariantywności, która zamiast linków budowana jest przez semantyczne reguły odnoszące się do stanu zaawansowania narracji, postępów bohaterów itp. Proces twórczy, w przypadku zastosowaniu storylets, może znacząco różnić się od standardowego rozrysowywania drzewek fabuły. Autorzy, którzy doskonale wiedzą, co chcą pisać mogą preferować storylets zamiast linków, każdą scenę mogą bowiem poprzedzić określeniem warunków na jakich przejście z niej do innych się odbywa. Twine pozwala na określenie warunków już na początku segmentu, następnie, po napisaniu jego treści, praca autora się w zasadzie kończy. Stworzone muszą być jednak segmenty, do których warunki się odnoszą. Jeśli treści jest wystarczająco dużo to przebieg lektury / rozgrywki sortuje się sam, tworząc w locie dozwolone połączenia między segmentami. W dokumentacji Harlowe widnieje taki przykład:
(storylet: when $season is "winter" and $married is false and visits is 0)
Jeśli powyższe makro zamieścimy na początku pasażu, to Twine, wykorzystując wbudowaną w storylet funkcję wyszukującą “lambda” pozwoli czytelnikowi przejść do kolejnego “otwartego”, a zatem spełniającego trzy powyższe warunki (jest zima, bohater nie jest w związku małżeńskim, a obecnego fragmentu jeszcze nie odwiedzono) segmentu oznaczonego jako storylet. Sortowanie takich segmentów, sprawdzanie, które są dostępne, a które nie, odbywa się w tle. Autor musi jedynie określić sposób w jaki sortowanie zostanie uruchomione (np. za pomocą makra “link-goto”). Użyte musi być też dodatkowe makro (open-storylets:):
(for: each _p, ...(open-storylets:)'s 1stTo5th)[(link-goto: _p's name) - ]
Powyższy kod iteruje po liście branych pod uwagę segmentów i wybiera z pierwszego, który jest dostępny (otwarty). Po dodaniu w tym samym pasażu tak uzbrojonego makra (open-storylets:) nasz oparty na storylets system zaczyna działać. Lektura w locie i dynamicznie dostosowuje się do wyborów czytelnika bądź do “zewnętrznej” sytuacji w świecie przedstawionym. Czy tego rodzaju system warunkowego wyświetlania się treści, oddalający się zarówno od struktur linkowych jak i prostych warunków opartych na makrach (if:) (else:), do którego potrzebne są lambdy, zagnieżdżone makra, iteracje po tablicach danych, może stanowić wiążącą alternatywę dla autorów? Czas pokaże.
Ulica Sienkiewicza- jubileusz
Mariusz Pisarski | 14.12.2022
Mija 20 lat od ukazania się Ulicy Sienkiewicza w Kielcach Radosława Nowakowskiego. Wielu z nas, przynajmniej pod kątem badawczym, wychowało się na tej niecodziennej, wyjątkowej, nie dającej się wyczerpać książce. Uczy nas ona do dziś, że interakcja, sprawczość i zanurzenie nie są wynalazkiem tekstów elektronicznych, ale istnieją w tradycji od zawsze. Późna epoka druku, której przejawem są między innym tanie technologie drukarskie dostępne dla przeciętnego zjadacza chleba (czytaj - artysty), pokazała, jak daleko można się posunąć w medium druku i przywrócić mu magię nie odbiegającą od tej, z która obnosi się medium cyfrowe.

Miałem niedawno okazję odwiedzić Radosława Nowakowskiego w jego domu-pracowni w Dąbrowie Dolnej. Pisarz pracuje nad specjalnym, jubileuszowym wydaniem Ulicy Sienkiewicza…. Jak przystało na Nowakowskiego, jubileusze wydanie będzie czymś naprawdę specjalnym. Otóż autor podjął się nowego sczytania głównej ulicy Kielc w dwadzieścia lat po oryginalnych, pierwotnych sesjach.
Jubileuszowa Ulicy Sienkiewicza… będzie zatem tą samą ulicą, ale 20 lat później. Nie mogę się doczekać, by odnaleźć na niej swoje ulubione miejsca, jak na przykład ukraińskie delikatesy….. Póki co, przed Nowakowskim sporo pracy, gdyż jubileuszowe wydanie będzie miało oczywiście świeży tekst, a także - nowy protokół lektury. Oficjalna i uroczysta premiera już w czerwcu. Zdaje się, że władze miasta potraktują to wydarzenie z należytą czcią i oddaniem. Radku, powodzenia!
Przyjazne linki:
- Techsty
- Hipertekst
- Magazyn Techsty
- Ha-art
- Centrum Badań nad Literaturą Elektroniczną
- Instytut Kultury Współczesnej
Anglojęzyczne